{
"cells": [
{
"cell_type": "markdown",
"id": "b9e93184",
"metadata": {},
"source": [
"# 语法函数1-基础介绍\n",
"## 对象\n",
"- 一切都是对象\n",
" - R中存储的数据成为对象object,R语言数据处理实际上就是不断的创建和操控这些对象。\n",
"- 对象的创建和使用\n",
" - 创建一个R对象,首先确定一个名称,然后使用赋值操作符 <-,将数据赋值给它"
]
},
{
"cell_type": "markdown",
"id": "0cca4ee2",
"metadata": {},
"source": [
"#### 对象属性\n",
"所有R对象都有其属性,其中最重要的两个属性是类型和长度"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "bc2b28fa",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'double'"
],
"text/latex": [
"'double'"
],
"text/markdown": [
"'double'"
],
"text/plain": [
"[1] \"double\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"1"
],
"text/latex": [
"1"
],
"text/markdown": [
"1"
],
"text/plain": [
"[1] 1"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- 123\n",
"typeof(x) # 类型\n",
"length(x) # 长度"
]
},
{
"cell_type": "markdown",
"id": "f5ba2418",
"metadata": {},
"source": [
"## 向量\n",
"- 向量就像冰糖葫芦\n",
" - 可以用 c() 函数实现类似结构"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "0ba0b1ae",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'double'"
],
"text/latex": [
"'double'"
],
"text/markdown": [
"'double'"
],
"text/plain": [
"[1] \"double\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"5"
],
"text/latex": [
"5"
],
"text/markdown": [
"5"
],
"text/plain": [
"[1] 5"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c(3,4,5,6,7)\n",
"typeof(x)\n",
"length(x)\n",
"\n",
"# 这里的c就是 combine 或 concatenate 的意思\n",
"# 它要求元素之间用英文的逗号分隔\n",
"# 且元素的数据类型是统一的,比如这里都是数值\n",
"# c() 函数把一组数据聚合到了一起,就构成了一个向量。"
]
},
{
"cell_type": "markdown",
"id": "3813f644",
"metadata": {},
"source": [
"- 聚合成新向量\n",
" - c() 函数还可以把两个向量聚合成一个新的向量。"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "aa38782d",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3
- 4
- 5
- 6
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\item 5\n",
"\\item 6\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"5. 5\n",
"6. 6\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1 2 3 4 5 6"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"low <- c(1,2,3)\n",
"high <- c(4,5,6)\n",
"sequence <- c(low, high)\n",
"sequence"
]
},
{
"cell_type": "markdown",
"id": "3eaf00a1",
"metadata": {},
"source": [
"- 命名向量\n",
" - 相比与向量c(5, 6, 7, 8), 每个元素可以有自己的名字\n",
" - 个人评价:类似于`python`中的字典——键值对"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "8ac549fb",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"- a
- 5
- b
- 6
- c
- 7
- d
- 8
\n"
],
"text/latex": [
"\\begin{description*}\n",
"\\item[a] 5\n",
"\\item[b] 6\n",
"\\item[c] 7\n",
"\\item[d] 8\n",
"\\end{description*}\n"
],
"text/markdown": [
"a\n",
": 5b\n",
": 6c\n",
": 7d\n",
": 8\n",
"\n"
],
"text/plain": [
"a b c d \n",
"5 6 7 8 "
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c('a'=5, 'b'=6, 'c'=7, 'd'=8)\n",
"x"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "41213992",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"- a
- 5
- b
- 6
- c
- 7
- d
- 8
\n"
],
"text/latex": [
"\\begin{description*}\n",
"\\item[a] 5\n",
"\\item[b] 6\n",
"\\item[c] 7\n",
"\\item[d] 8\n",
"\\end{description*}\n"
],
"text/markdown": [
"a\n",
": 5b\n",
": 6c\n",
": 7d\n",
": 8\n",
"\n"
],
"text/plain": [
"a b c d \n",
"5 6 7 8 "
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# 或者\n",
"x <- c(5,6,7,8)\n",
"names(x) <- c('a','b','c','d')\n",
"x"
]
},
{
"cell_type": "markdown",
"id": "3c5b524d",
"metadata": {},
"source": [
"### 数值型向量\n",
"- 向量的元素都是数值类型,因此也叫数值型向量。\n",
" - 数值型的向量,有 integer 和 double 两种"
]
},
{
"cell_type": "code",
"execution_count": 37,
"id": "65bd341c",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'double'"
],
"text/latex": [
"'double'"
],
"text/markdown": [
"'double'"
],
"text/plain": [
"[1] \"double\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'numeric'"
],
"text/latex": [
"'numeric'"
],
"text/markdown": [
"'numeric'"
],
"text/plain": [
"[1] \"numeric\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'numeric'"
],
"text/latex": [
"'numeric'"
],
"text/markdown": [
"'numeric'"
],
"text/plain": [
"[1] \"numeric\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c(1,5,2,3)\n",
"typeof(x)\n",
"x <- c(1.5,-0.5,2,3)\n",
"class(x)\n",
"x <- c(3e+06, 1.23e2)\n",
"class(x)"
]
},
{
"cell_type": "markdown",
"id": "0d206a5b",
"metadata": {},
"source": [
" - seq() 函数可以生成等差数列,\n",
" - from 参数指定数列的起始值,to 参数指定数列的终止值,by 参数指定数值的间距"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "06cec7b8",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 0
- 0.5
- 1
- 1.5
- 2
- 2.5
- 3
- 3.5
- 4
- 4.5
- 5
- 5.5
- 6
- 6.5
- 7
- 7.5
- 8
- 8.5
- 9
- 9.5
- 10
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 0\n",
"\\item 0.5\n",
"\\item 1\n",
"\\item 1.5\n",
"\\item 2\n",
"\\item 2.5\n",
"\\item 3\n",
"\\item 3.5\n",
"\\item 4\n",
"\\item 4.5\n",
"\\item 5\n",
"\\item 5.5\n",
"\\item 6\n",
"\\item 6.5\n",
"\\item 7\n",
"\\item 7.5\n",
"\\item 8\n",
"\\item 8.5\n",
"\\item 9\n",
"\\item 9.5\n",
"\\item 10\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 0\n",
"2. 0.5\n",
"3. 1\n",
"4. 1.5\n",
"5. 2\n",
"6. 2.5\n",
"7. 3\n",
"8. 3.5\n",
"9. 4\n",
"10. 4.5\n",
"11. 5\n",
"12. 5.5\n",
"13. 6\n",
"14. 6.5\n",
"15. 7\n",
"16. 7.5\n",
"17. 8\n",
"18. 8.5\n",
"19. 9\n",
"20. 9.5\n",
"21. 10\n",
"\n",
"\n"
],
"text/plain": [
" [1] 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0\n",
"[16] 7.5 8.0 8.5 9.0 9.5 10.0"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"s1 <- seq(from=0, to=10, by=0.5)\n",
"s1"
]
},
{
"cell_type": "markdown",
"id": "76c490fe",
"metadata": {},
"source": [
" - rep() 是 repeat(重复)的意思,可以用于产生重复出现的数字序列:\n",
" - x 用于重复的向量,times 参数可以指定要生成的个数,each 参数可以指定每个元素重复的次数"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "8d1d09e8",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 0
- 1
- 0
- 1
- 0
- 1
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 0\n",
"\\item 1\n",
"\\item 0\n",
"\\item 1\n",
"\\item 0\n",
"\\item 1\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 0\n",
"2. 1\n",
"3. 0\n",
"4. 1\n",
"5. 0\n",
"6. 1\n",
"\n",
"\n"
],
"text/plain": [
"[1] 0 1 0 1 0 1"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 0
- 0
- 0
- 1
- 1
- 1
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 0\n",
"\\item 0\n",
"\\item 0\n",
"\\item 1\n",
"\\item 1\n",
"\\item 1\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 0\n",
"2. 0\n",
"3. 0\n",
"4. 1\n",
"5. 1\n",
"6. 1\n",
"\n",
"\n"
],
"text/plain": [
"[1] 0 0 0 1 1 1"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"s2 <- rep(x=c(0,1), times=3)\n",
"s2\n",
"\n",
"s3 <- rep(x=c(0,1), each=3)\n",
"s3"
]
},
{
"cell_type": "markdown",
"id": "c8da6aa5",
"metadata": {},
"source": [
" - m:n,如果单纯是要生成数值间距为1的数列,用 m:n 更快捷,\n",
" - 它产生从 m 到 n 的间距为1的数列"
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "8811a6d9",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 0\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\item 5\n",
"\\item 6\n",
"\\item 7\n",
"\\item 8\n",
"\\item 9\n",
"\\item 10\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 0\n",
"2. 1\n",
"3. 2\n",
"4. 3\n",
"5. 4\n",
"6. 5\n",
"7. 6\n",
"8. 7\n",
"9. 8\n",
"10. 9\n",
"11. 10\n",
"\n",
"\n"
],
"text/plain": [
" [1] 0 1 2 3 4 5 6 7 8 9 10"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"s4 <- 0:10\n",
"s4"
]
},
{
"cell_type": "markdown",
"id": "e23c3729",
"metadata": {},
"source": [
"### 字符串向量\n",
"- 字符串(String)数据类型,实际上就是文本类型,必须用单引号或者是双引号包含"
]
},
{
"cell_type": "code",
"execution_count": 18,
"id": "932b1683",
"metadata": {},
"outputs": [],
"source": [
"x <- c(\"a\", \"b\", \"c\") \n",
"x <- c('Alice', 'Bob', 'Charlie', 'Dave') \n",
"x <- c(\"hello\", \"baby\", \"I love you!\") "
]
},
{
"cell_type": "code",
"execution_count": 35,
"id": "16ef3749",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'character'"
],
"text/latex": [
"'character'"
],
"text/markdown": [
"'character'"
],
"text/plain": [
"[1] \"character\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'numeric'"
],
"text/latex": [
"'numeric'"
],
"text/markdown": [
"'numeric'"
],
"text/plain": [
"[1] \"numeric\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"## x1是字符串型向量,x2是数值型向量\n",
"x1 <- c(\"1\", \"2\", \"3\")\n",
"x2 <- c(1, 2, 3)\n",
"class(x1)\n",
"class(x2)"
]
},
{
"cell_type": "markdown",
"id": "91a33837",
"metadata": {},
"source": [
"### 逻辑型向量\n",
"- 逻辑型常称为布尔型(Boolean), 它的常量值只有`TRUE`和`FALSE`。\n",
"- TRUE和FALSE必须都大写"
]
},
{
"cell_type": "markdown",
"id": "7be37c4b",
"metadata": {},
"source": [
"### 因子型向量\n",
"- 因子型可以看作是字符串向量的增强版,它是带有层级(Levels)的字符串向量。\n",
"- 使用`factor()`函数可以将字符串向量转换成因子型向量,即可用`levels`参数指定顺序"
]
},
{
"cell_type": "code",
"execution_count": 24,
"id": "9461f626",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 'spring'
- 'summer'
- 'autumn'
- 'winter'
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 'spring'\n",
"\\item 'summer'\n",
"\\item 'autumn'\n",
"\\item 'winter'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 'spring'\n",
"2. 'summer'\n",
"3. 'autumn'\n",
"4. 'winter'\n",
"\n",
"\n"
],
"text/plain": [
"[1] \"spring\" \"summer\" \"autumn\" \"winter\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'character'"
],
"text/latex": [
"'character'"
],
"text/markdown": [
"'character'"
],
"text/plain": [
"[1] \"character\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- spring
- summer
- autumn
- winter
\n",
"\n",
"\n",
"\t\n",
"\t\tLevels:\n",
"\t
\n",
"\t\n",
"\t- 'summer'
- 'winter'
- 'spring'
- 'autumn'
\n",
" "
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item spring\n",
"\\item summer\n",
"\\item autumn\n",
"\\item winter\n",
"\\end{enumerate*}\n",
"\n",
"\\emph{Levels}: \\begin{enumerate*}\n",
"\\item 'summer'\n",
"\\item 'winter'\n",
"\\item 'spring'\n",
"\\item 'autumn'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. spring\n",
"2. summer\n",
"3. autumn\n",
"4. winter\n",
"\n",
"\n",
"\n",
"**Levels**: 1. 'summer'\n",
"2. 'winter'\n",
"3. 'spring'\n",
"4. 'autumn'\n",
"\n",
"\n"
],
"text/plain": [
"[1] spring summer autumn winter\n",
"Levels: summer winter spring autumn"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'integer'"
],
"text/latex": [
"'integer'"
],
"text/markdown": [
"'integer'"
],
"text/plain": [
"[1] \"integer\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"four_seasons <- c(\"spring\", \"summer\", \"autumn\", \"winter\")\n",
"four_seasons\n",
"typeof(four_seasons)\n",
"\n",
"four_seasons_factor <- factor(four_seasons, \n",
" levels = c(\"summer\", \"winter\", \"spring\", \"autumn\"))\n",
"four_seasons_factor\n",
"typeof(four_seasons_factor)"
]
},
{
"cell_type": "markdown",
"id": "57ca82fa",
"metadata": {},
"source": [
"### 强制转换\n",
"- 矢量中的元素必须是相同的类型,但如果不一样呢,会发生什么? \n",
"- 这个时候R会强制转换成相同的类型。这就涉及数据类型的转换层级\n",
" - character > numeric > logical\n",
" - double > integer"
]
},
{
"cell_type": "code",
"execution_count": 28,
"id": "edb1c1ec",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- '1'
- 'foo'
- 'TRUE'
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item '1'\n",
"\\item 'foo'\n",
"\\item 'TRUE'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. '1'\n",
"2. 'foo'\n",
"3. 'TRUE'\n",
"\n",
"\n"
],
"text/plain": [
"[1] \"1\" \"foo\" \"TRUE\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 7
- 1
- 0
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 7\n",
"\\item 1\n",
"\\item 0\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 7\n",
"2. 1\n",
"3. 0\n",
"\n",
"\n"
],
"text/plain": [
"[1] 7 1 0"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3.14159265358979
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3.14159265358979\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3.14159265358979\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1.000000 2.000000 3.141593"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"c(1, \"foo\", TRUE) # 强制转换成字符串类型\n",
"c(7, TRUE, FALSE) # 强制转换成数值型\n",
"c(1L, 2, pi) # 强制转换成双精度的数值型"
]
},
{
"cell_type": "markdown",
"id": "57a1b078",
"metadata": {},
"source": [
"## 数据结构\n",
"- 向量\n",
"- 矩阵 matrix\n",
"- 列表 list\n",
"- 数据框 dataframe"
]
},
{
"cell_type": "markdown",
"id": "821210ab",
"metadata": {},
"source": [
"### 矩阵\n",
"- 矩阵可以存储行(row)和列(column)二维的数据。\n",
"- 实际上是向量的另一种表现形式,也就说它的本质还是向量,一维的向量用二维的方式呈现\n",
"- 矩阵可以用`matrix()`函数创建,第一个位置的参数是用于创建矩阵的向量\n",
"- 默认情况是竖着排,第一列排完再第二列这样,可用`byrow=TRUE`指定横着排,第一行排完排第二行"
]
},
{
"cell_type": "code",
"execution_count": 40,
"id": "5c645061",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A matrix: 2 × 3 of type dbl\n",
"\n",
"\t| 2 | 3 | 5 |
\n",
"\t| 4 | 1 | 7 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 2 × 3 of type dbl\n",
"\\begin{tabular}{lll}\n",
"\t 2 & 3 & 5\\\\\n",
"\t 4 & 1 & 7\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 2 × 3 of type dbl\n",
"\n",
"| 2 | 3 | 5 |\n",
"| 4 | 1 | 7 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 2 3 5 \n",
"[2,] 4 1 7 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A matrix: 2 × 3 of type dbl\n",
"\n",
"\t| 2 | 4 | 3 |
\n",
"\t| 1 | 5 | 7 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 2 × 3 of type dbl\n",
"\\begin{tabular}{lll}\n",
"\t 2 & 4 & 3\\\\\n",
"\t 1 & 5 & 7\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 2 × 3 of type dbl\n",
"\n",
"| 2 | 4 | 3 |\n",
"| 1 | 5 | 7 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 2 4 3 \n",
"[2,] 1 5 7 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 'matrix'
- 'array'
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 'matrix'\n",
"\\item 'array'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 'matrix'\n",
"2. 'array'\n",
"\n",
"\n"
],
"text/plain": [
"[1] \"matrix\" \"array\" "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"6"
],
"text/latex": [
"6"
],
"text/markdown": [
"6"
],
"text/plain": [
"[1] 6"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 2
- 3
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 2\n",
"\\item 3\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 2\n",
"2. 3\n",
"\n",
"\n"
],
"text/plain": [
"[1] 2 3"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"m <- matrix(c(2,4,3,1,5,7),\n",
" nrow=2,\n",
" ncol=3)\n",
"m\n",
"\n",
"m1 <- matrix(c(2,4,3,1,5,7),\n",
" nrow=2,\n",
" ncol=3,\n",
" byrow=TRUE)\n",
"m1\n",
"class(m1) # 类型\n",
"length(m1) # 长度\n",
"dim(m1) # 维度"
]
},
{
"cell_type": "markdown",
"id": "07065034",
"metadata": {},
"source": [
"### 列表\n",
"- 如果我们想要装更多的东西,可以想象有一个小火车,小火车的每节车厢是独立的,因此每节车厢装的东西可以不一样。这种结构装载数据的能力很强大,称之为列表。\n",
" - 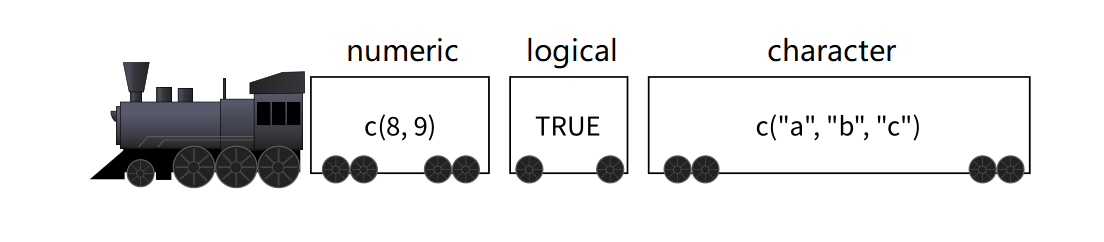\n",
"- 我们可以使用`list()`函数创建列表,和python的list不太一样\n",
"- `c()`函数创建向量 对比`list()`函数创建列表\n",
" - 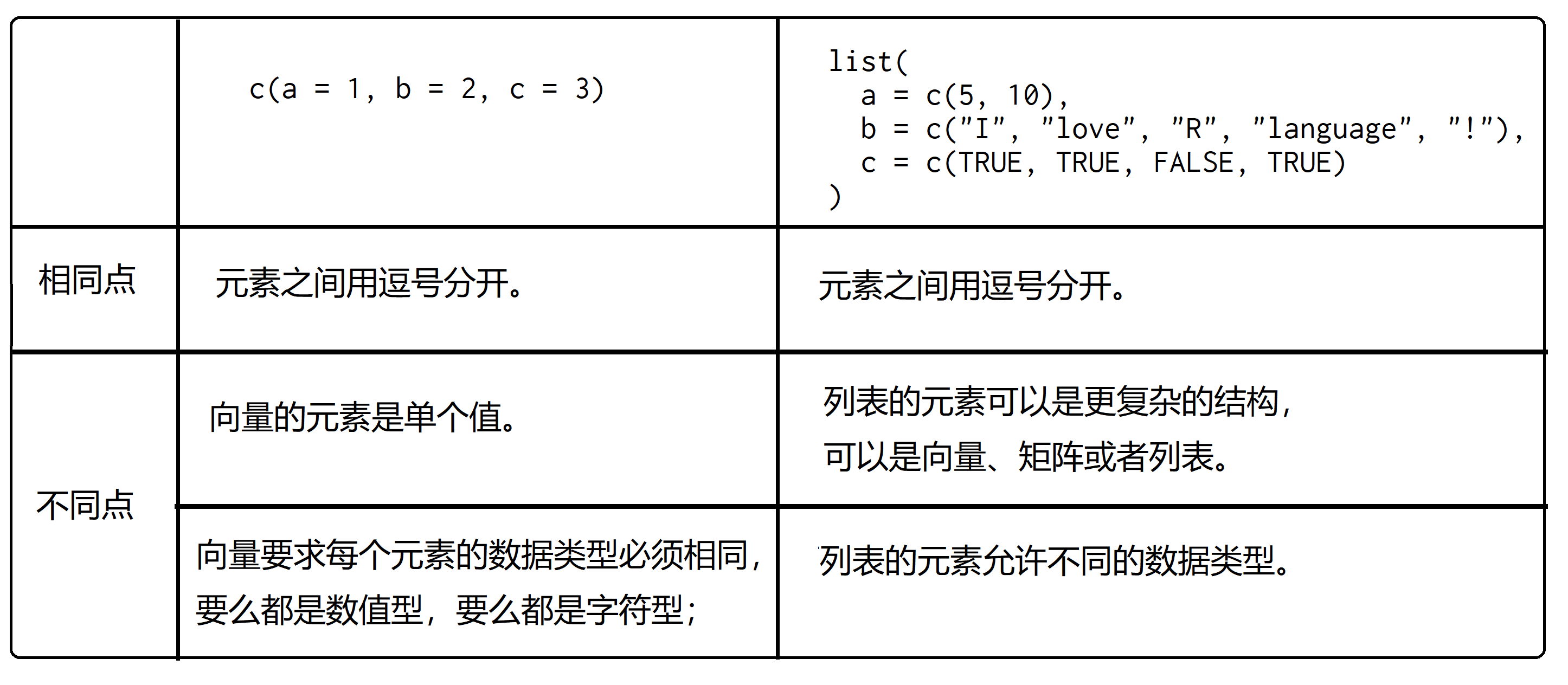"
]
},
{
"cell_type": "code",
"execution_count": 44,
"id": "9bc7be82",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\t- $a
\n",
"\t\t- \n",
"
- 5
- 10
\n",
" \n",
"\t- $b
\n",
"\t\t- \n",
"
- 'I'
- 'love'
- 'R'
- 'language'
- '!'
\n",
" \n",
"\t- $c
\n",
"\t\t- \n",
"
- TRUE
- TRUE
- FALSE
- TRUE
\n",
" \n",
"
\n"
],
"text/latex": [
"\\begin{description}\n",
"\\item[\\$a] \\begin{enumerate*}\n",
"\\item 5\n",
"\\item 10\n",
"\\end{enumerate*}\n",
"\n",
"\\item[\\$b] \\begin{enumerate*}\n",
"\\item 'I'\n",
"\\item 'love'\n",
"\\item 'R'\n",
"\\item 'language'\n",
"\\item '!'\n",
"\\end{enumerate*}\n",
"\n",
"\\item[\\$c] \\begin{enumerate*}\n",
"\\item TRUE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\end{enumerate*}\n",
"\n",
"\\end{description}\n"
],
"text/markdown": [
"$a\n",
": 1. 5\n",
"2. 10\n",
"\n",
"\n",
"\n",
"$b\n",
": 1. 'I'\n",
"2. 'love'\n",
"3. 'R'\n",
"4. 'language'\n",
"5. '!'\n",
"\n",
"\n",
"\n",
"$c\n",
": 1. TRUE\n",
"2. TRUE\n",
"3. FALSE\n",
"4. TRUE\n",
"\n",
"\n",
"\n",
"\n",
"\n"
],
"text/plain": [
"$a\n",
"[1] 5 10\n",
"\n",
"$b\n",
"[1] \"I\" \"love\" \"R\" \"language\" \"!\" \n",
"\n",
"$c\n",
"[1] TRUE TRUE FALSE TRUE\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 5
- 10
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 5\n",
"\\item 10\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 5\n",
"2. 10\n",
"\n",
"\n"
],
"text/plain": [
"[1] 5 10"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'love'"
],
"text/latex": [
"'love'"
],
"text/markdown": [
"'love'"
],
"text/plain": [
"[1] \"love\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"list1 <- list(a=c(5, 10),\n",
" b=c(\"I\", \"love\", \"R\", \"language\", \"!\"),\n",
" c=c(TRUE, TRUE, FALSE, TRUE))\n",
"list1\n",
"list1$a\n",
"list1$`b[2]"
]
},
{
"cell_type": "markdown",
"id": "15913b82",
"metadata": {},
"source": [
"### 数据框\n",
"- 列表可以想象成一个小火车,如果每节车厢装的都是向量而且等长,那么这种特殊形式的列表就变成了数据框\n",
"- 数据框是一种特殊的列表,我们可以使用`data.frame()`函数构建数据框\n",
"\n",
"#### 属性"
]
},
{
"cell_type": "code",
"execution_count": 48,
"id": "00b0411a",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 4\n",
"\n",
"\t| name | age | marriage | color |
|---|
\n",
"\t| <chr> | <dbl> | <lgl> | <chr> |
|---|
\n",
"\n",
"\n",
"\t| Alice | 3 | TRUE | red |
\n",
"\t| Bob | 34 | FALSE | blue |
\n",
"\t| Carl | 23 | TRUE | orange |
\n",
"\t| Dave | 25 | FALSE | purple |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 4\n",
"\\begin{tabular}{llll}\n",
" name & age & marriage & color\\\\\n",
" & & & \\\\\n",
"\\hline\n",
"\t Alice & 3 & TRUE & red \\\\\n",
"\t Bob & 34 & FALSE & blue \\\\\n",
"\t Carl & 23 & TRUE & orange\\\\\n",
"\t Dave & 25 & FALSE & purple\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 4\n",
"\n",
"| name <chr> | age <dbl> | marriage <lgl> | color <chr> |\n",
"|---|---|---|---|\n",
"| Alice | 3 | TRUE | red |\n",
"| Bob | 34 | FALSE | blue |\n",
"| Carl | 23 | TRUE | orange |\n",
"| Dave | 25 | FALSE | purple |\n",
"\n"
],
"text/plain": [
" name age marriage color \n",
"1 Alice 3 TRUE red \n",
"2 Bob 34 FALSE blue \n",
"3 Carl 23 TRUE orange\n",
"4 Dave 25 FALSE purple"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'data.frame'"
],
"text/latex": [
"'data.frame'"
],
"text/markdown": [
"'data.frame'"
],
"text/plain": [
"[1] \"data.frame\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"4"
],
"text/latex": [
"4"
],
"text/markdown": [
"4"
],
"text/plain": [
"[1] 4"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"4"
],
"text/latex": [
"4"
],
"text/markdown": [
"4"
],
"text/plain": [
"[1] 4"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"df <- data.frame(\n",
"name = c(\"Alice\", \"Bob\", \"Carl\", \"Dave\"),\n",
"age = c(3, 34, 23, 25),\n",
"marriage = c(TRUE, FALSE, TRUE, FALSE),\n",
"color = c(\"red\", \"blue\", \"orange\", \"purple\")\n",
")\n",
"df\n",
"class(df) # 类型\n",
"nrow(df) # 维度\n",
"ncol(df) # 维度\n"
]
},
{
"cell_type": "markdown",
"id": "058465ab",
"metadata": {},
"source": [
"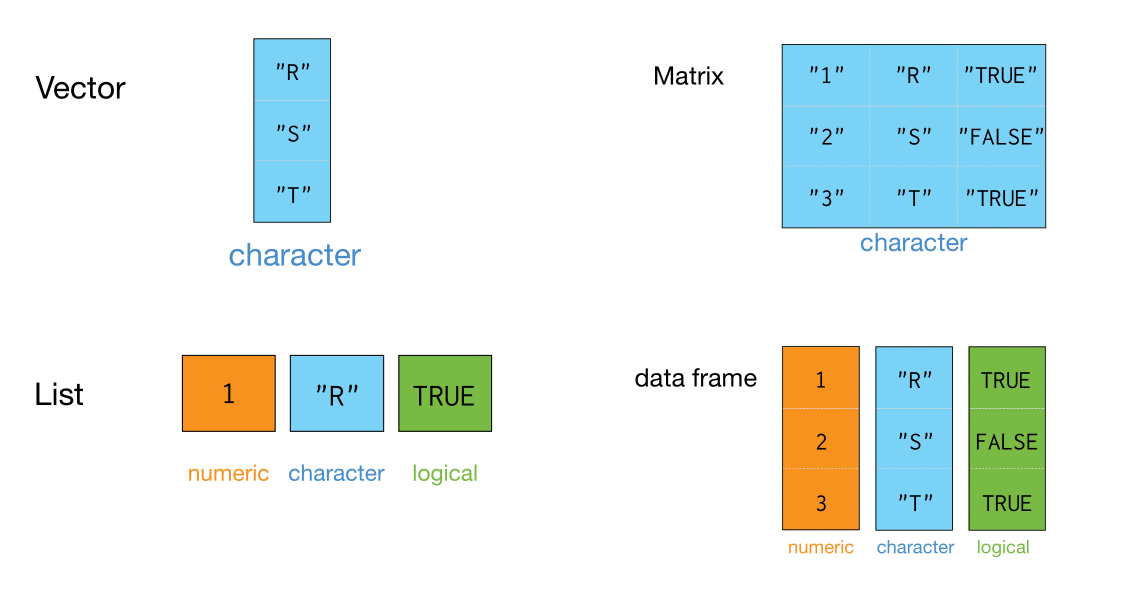"
]
},
{
"cell_type": "markdown",
"id": "245c74b5",
"metadata": {},
"source": [
"## 运算符及向量运算\n",
"- 算数运算符 + - x ➗\n",
"- 关系运算符 = > < !=\n",
"- 逻辑运算符 & |\n",
"- 其他运算符"
]
},
{
"cell_type": "markdown",
"id": "eee623a2",
"metadata": {},
"source": [
"### 算数运算符\n",
"- `+ - * / `\n",
"- 循环补齐\n",
" - 做算术运算时,当两个向量长度相等的时候,就一一对应的完成计算;\n",
" - 当两个向量长度不相等的时候,短的向量会`循环补齐`,保持与长向量的长度一致后,再做运算\n",
" - 需要长向量是短向量的整数倍才能运算"
]
},
{
"cell_type": "code",
"execution_count": 50,
"id": "5b2ee082",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 11
- 22
- 31
- 42
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 11\n",
"\\item 22\n",
"\\item 31\n",
"\\item 42\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 11\n",
"2. 22\n",
"3. 31\n",
"4. 42\n",
"\n",
"\n"
],
"text/plain": [
"[1] 11 22 31 42"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c(1,2)\n",
"y <- c(10,20,30,40)\n",
"x+y"
]
},
{
"cell_type": "markdown",
"id": "372c0534",
"metadata": {},
"source": [
"### 关系运算符\n",
"- 将第一向量的每个元素与第二向量的相应元素进行比较,比较的结果是布尔值,布尔值是“真” TRUE 或“假” FALSE 中的一个。\n",
"- `< > = !=`"
]
},
{
"cell_type": "code",
"execution_count": 52,
"id": "fd514a29",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- FALSE
- FALSE
- FALSE
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item FALSE\n",
"\\item FALSE\n",
"\\item FALSE\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. FALSE\n",
"2. FALSE\n",
"3. FALSE\n",
"\n",
"\n"
],
"text/plain": [
"[1] FALSE FALSE FALSE"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# 检查第一个向量的每个元素是否等于第二个向量的相应元素。\n",
"a <- c(1, 2, 3)\n",
"b <- c(4, 5, 6)\n",
"a == b"
]
},
{
"cell_type": "markdown",
"id": "80dc5600",
"metadata": {},
"source": [
"### 逻辑运算符\n",
"- 一般适用于逻辑类型的向量\n",
"- `& | !` ! 为逻辑非运算符。 对于向量的每个元素,给出相反的逻辑值。\n",
"- 逻辑运算符`&&`和`||`只考虑向量的第一个元素,给出单个元素的向量作为输出"
]
},
{
"cell_type": "code",
"execution_count": 55,
"id": "3b364dc9",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- FALSE
- TRUE
- TRUE
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\item TRUE\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. FALSE\n",
"2. TRUE\n",
"3. TRUE\n",
"\n",
"\n"
],
"text/plain": [
"[1] FALSE TRUE TRUE"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"Warning message in a && b:\n",
"“'length(x) = 3 > 1' in coercion to 'logical(1)'”\n",
"Warning message in a && b:\n",
"“'length(x) = 3 > 1' in coercion to 'logical(1)'”\n"
]
},
{
"data": {
"text/html": [
"FALSE"
],
"text/latex": [
"FALSE"
],
"text/markdown": [
"FALSE"
],
"text/plain": [
"[1] FALSE"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"Warning message in a || b:\n",
"“'length(x) = 3 > 1' in coercion to 'logical(1)'”\n"
]
},
{
"data": {
"text/html": [
"TRUE"
],
"text/latex": [
"TRUE"
],
"text/markdown": [
"TRUE"
],
"text/plain": [
"[1] TRUE"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"a <- c(TRUE, FALSE, FALSE)\n",
"!a\n",
"\n",
"a <- c(TRUE, FALSE, FALSE)\n",
"b <- c(FALSE, TRUE, FALSE)\n",
"a && b\n",
"\n",
"a <- c(TRUE, FALSE, FALSE)\n",
"b <- c(FALSE, TRUE, FALSE)\n",
"a || b"
]
},
{
"cell_type": "markdown",
"id": "cf5b51a1",
"metadata": {},
"source": [
"### 其他运算符\n",
"- `:`冒号运算符。按顺序创建一个**整数**序列\n",
"- `%in%` 此运算符用于判断元素是否属于向量\n",
"- `is.na()`判断是否为缺失值,`R` 里缺失值用`NA`表示,`NA`的意思就是 `not available` 或者 `not applicable`."
]
},
{
"cell_type": "code",
"execution_count": 64,
"id": "248f1da9",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\item 5\n",
"\\item 6\n",
"\\item 7\n",
"\\item 8\n",
"\\item 9\n",
"\\item 10\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"5. 5\n",
"6. 6\n",
"7. 7\n",
"8. 8\n",
"9. 9\n",
"10. 10\n",
"\n",
"\n"
],
"text/plain": [
" [1] 1 2 3 4 5 6 7 8 9 10"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'integer'"
],
"text/latex": [
"'integer'"
],
"text/markdown": [
"'integer'"
],
"text/plain": [
"[1] \"integer\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- TRUE
- TRUE
- FALSE
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item TRUE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. TRUE\n",
"2. TRUE\n",
"3. FALSE\n",
"\n",
"\n"
],
"text/plain": [
"[1] TRUE TRUE FALSE"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- FALSE
- FALSE
- FALSE
- TRUE
- FALSE
- TRUE
- FALSE
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item FALSE\n",
"\\item FALSE\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. FALSE\n",
"2. FALSE\n",
"3. FALSE\n",
"4. TRUE\n",
"5. FALSE\n",
"6. TRUE\n",
"7. FALSE\n",
"\n",
"\n"
],
"text/plain": [
"[1] FALSE FALSE FALSE TRUE FALSE TRUE FALSE"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- TRUE
- TRUE
- FALSE
- TRUE
- FALSE
- TRUE
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item TRUE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\item TRUE\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. TRUE\n",
"2. TRUE\n",
"3. FALSE\n",
"4. TRUE\n",
"5. FALSE\n",
"6. TRUE\n",
"\n",
"\n"
],
"text/plain": [
"[1] TRUE TRUE FALSE TRUE FALSE TRUE"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# :\n",
"a <- 1:10\n",
"a\n",
"typeof(a)\n",
"\n",
"# %in%\n",
"c(2,3,7) %in% c(1,2,3,4,5)\n",
"\n",
"# is.na()\n",
"is.na(c(1,2,3,NA,4,NA,5))\n",
"x <- c(1,2,NA,4,NA,6)\n",
"!is.na(x)"
]
},
{
"cell_type": "markdown",
"id": "4e647d0d",
"metadata": {},
"source": [
"- `seq()`函数也能产生序列\n",
"- 注意到a是整数类型,而b是双精度的数值型"
]
},
{
"cell_type": "code",
"execution_count": 61,
"id": "72b18bfa",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\item 5\n",
"\\item 6\n",
"\\item 7\n",
"\\item 8\n",
"\\item 9\n",
"\\item 10\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"5. 5\n",
"6. 6\n",
"7. 7\n",
"8. 8\n",
"9. 9\n",
"10. 10\n",
"\n",
"\n"
],
"text/plain": [
" [1] 1 2 3 4 5 6 7 8 9 10"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"'integer'"
],
"text/latex": [
"'integer'"
],
"text/markdown": [
"'integer'"
],
"text/plain": [
"[1] \"integer\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"b <- seq(1,10,1)\n",
"b\n",
"typeof(b)"
]
},
{
"cell_type": "markdown",
"id": "14d09e16",
"metadata": {},
"source": [
"### 特殊值\n",
"- R 语言里还有一些特殊的值: `Inf, NaN, NA 和 NULL`\n",
"- `Inf`, 是Infinity的简写,表示无限大;`-Inf`表示无限小\n",
"- `NaN`, 是Not a Number的简写,表示这个数字没有数学定义\n",
"- `NA`, 是Not available的简写,表示缺失状态\n",
"- `NULL`, 是No value的意思,表示没有值,或者空值的意思,表示变量实际上没有任何值,或者甚至不存在。"
]
},
{
"cell_type": "code",
"execution_count": 71,
"id": "4e078920",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"Inf"
],
"text/latex": [
"Inf"
],
"text/markdown": [
"Inf"
],
"text/plain": [
"[1] Inf"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"-Inf"
],
"text/latex": [
"-Inf"
],
"text/markdown": [
"-Inf"
],
"text/plain": [
"[1] -Inf"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"NaN"
],
"text/latex": [
"NaN"
],
"text/markdown": [
"NaN"
],
"text/plain": [
"[1] NaN"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/plain": [
"NULL"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 1
- <NA>
- 3
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item \n",
"\\item 3\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. <NA>\n",
"3. 3\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1 NA 3"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Inf\n",
"1/0\n",
"-1/0\n",
"\n",
"# NaN\n",
"0/0\n",
"\n",
"# NULL\n",
"c( )\n",
"\n",
"# NA\n",
"c(1,NA,3)"
]
},
{
"cell_type": "code",
"execution_count": 72,
"id": "95d2b3bf",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"FALSE"
],
"text/latex": [
"FALSE"
],
"text/markdown": [
"FALSE"
],
"text/plain": [
"[1] FALSE"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"a <- 1:10\n",
"b <- seq(1,10,1)\n",
"\n",
"identical(a,b)"
]
},
{
"cell_type": "markdown",
"id": "d76e2f5e",
"metadata": {},
"source": [
"## 函数\n",
"### 基础函数\n",
"- `print()` 打印\n",
"- `sqrt()` 求开方\n",
"- `sd()` 标准差函数\n",
"- `log()` 求自然对数\n",
"- `sum()` 求和\n",
"- `mean()` 求平均值\n",
"- `min()` 最小值\n",
"- `max()` 最大值\n",
"- `length()` 计算向量个数\n",
"- `sort()` 排序\n",
"- `nique()` 去重\n",
"- `quantile()` 求分位数\n",
"- `is.numeric()` 判断是否为数值型\n",
"- `is.character()` 判断是否为字符串型\n",
"- `as.character()` 转为字符串型"
]
},
{
"cell_type": "markdown",
"id": "7d89b0cd",
"metadata": {},
"source": [
"### 向量的函数\n",
"- 用在向量上的函数,可以分为向量化函数(vectorized function)和汇总类函数(summary function)\n",
"- 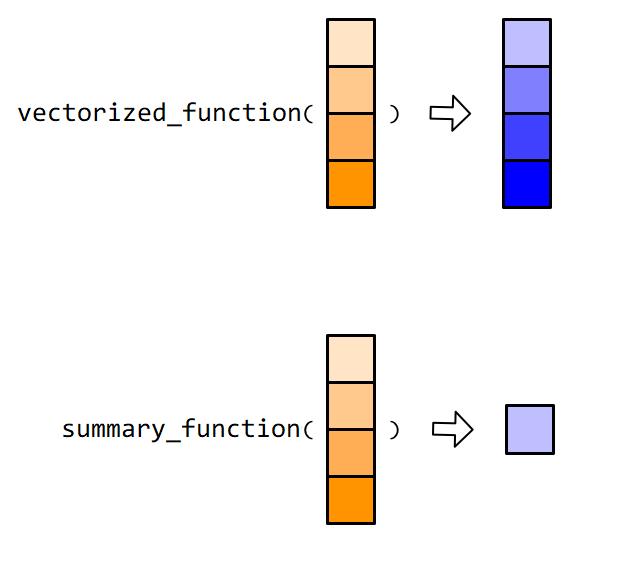\n",
"- 这两类函数在`Tidyverse`框架中,应用非常广泛。\n",
"- 当然,也会有例外,比如`unique()`函数,它返回的向量通常不会与输入的向量等长,既不属于向量化函数,也不属于汇总类函数。"
]
},
{
"cell_type": "code",
"execution_count": 76,
"id": "cef52a29",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 9
- 54
- 69
- 86
- 14
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 9\n",
"\\item 54\n",
"\\item 69\n",
"\\item 86\n",
"\\item 14\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 9\n",
"2. 54\n",
"3. 69\n",
"4. 86\n",
"5. 14\n",
"\n",
"\n"
],
"text/plain": [
"[1] 9 54 69 86 14"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 2
- 3
- 7
- 8
- 9
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 2\n",
"\\item 3\n",
"\\item 7\n",
"\\item 8\n",
"\\item 9\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 2\n",
"2. 3\n",
"3. 7\n",
"4. 8\n",
"5. 9\n",
"\n",
"\n"
],
"text/plain": [
"[1] 2 3 7 8 9"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- -3.8
- 1.2
- 2.2
- 3.2
- -2.8
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item -3.8\n",
"\\item 1.2\n",
"\\item 2.2\n",
"\\item 3.2\n",
"\\item -2.8\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. -3.8\n",
"2. 1.2\n",
"3. 2.2\n",
"4. 3.2\n",
"5. -2.8\n",
"\n",
"\n"
],
"text/plain": [
"[1] -3.8 1.2 2.2 3.2 -2.8"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- -1.22010646822908
- 0.385296779440761
- 0.706377428974729
- 1.0274580785087
- -0.89902581869511
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item -1.22010646822908\n",
"\\item 0.385296779440761\n",
"\\item 0.706377428974729\n",
"\\item 1.0274580785087\n",
"\\item -0.89902581869511\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. -1.22010646822908\n",
"2. 0.385296779440761\n",
"3. 0.706377428974729\n",
"4. 1.0274580785087\n",
"5. -0.89902581869511\n",
"\n",
"\n"
],
"text/plain": [
"[1] -1.2201065 0.3852968 0.7063774 1.0274581 -0.8990258"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c(2,7,8,9,3)\n",
"x^2 + 5\n",
"\n",
"sort(x)\n",
"\n",
"x - mean(x)\n",
"\n",
"# 向量标准化(向量减去其均值之后,除以标准差)\n",
"(x -mean(x))/sd(x)"
]
},
{
"cell_type": "markdown",
"id": "9adcce5e",
"metadata": {},
"source": [
"### 自定义函数\n",
"- **创建**,由`function(...)`创建一个函数\n",
"- **参数**,由`(...)`里指定参数,比如`function(x)`中的参数为 `x`\n",
"- **函数主体**,一般情况下,在`function(...)`后跟随一对大括号`{ }`,在大括号里声明具体函数功能,在代码最后一行,可以用`return`返回计算后的值。当然,如果函数的目的只是返回最后一行代码计算的值,这个`return`可以省略。\n",
"- **函数名**,`function() { }`赋值给新对象,比如这里的`my_std`,相当于给函数取一名字,方便以后使用。\n",
"- **函数调用**,现在这个函数名字叫`my_std`,需要用这个函数的时候,就调用它的名字`my_std()`。\n",
"\n",
"和`python`的`def`创建的函数差不多,创建形式不同,但应用方式一样,元素差不多"
]
},
{
"cell_type": "code",
"execution_count": 79,
"id": "3ab4d86e",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- -1.22010646822908
- 0.385296779440761
- 0.706377428974729
- 1.0274580785087
- -0.89902581869511
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item -1.22010646822908\n",
"\\item 0.385296779440761\n",
"\\item 0.706377428974729\n",
"\\item 1.0274580785087\n",
"\\item -0.89902581869511\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. -1.22010646822908\n",
"2. 0.385296779440761\n",
"3. 0.706377428974729\n",
"4. 1.0274580785087\n",
"5. -0.89902581869511\n",
"\n",
"\n"
],
"text/plain": [
"[1] -1.2201065 0.3852968 0.7063774 1.0274581 -0.8990258"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"y <- c(2,7,8,9,3)\n",
"\n",
"my_std <- function(x){\n",
" (x - mean(x)) / sd(x)\n",
"}\n",
"\n",
"my_std(y)"
]
},
{
"attachments": {
"image.png": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAasAAABSCAYAAADq+/sIAAAaU0lEQVR4Ae1dvWsqTxf+/YPbLAgiSAotJIUpTGMam622sYmNTSzSpQiBIAQECVyQgBCQW5hCUuQWWrymMI3V8zIfZ3b2S01cc9fcc4ur7s7OzjxnM8+eM+fjP/A/RoARYATyjMBqjG69jNNGB0+r7Ae6uKmj4Dg4v5ln37npcYS266Dg+ngyx/jLZxD47zONuS0jwAgwAj8LgSmuyg4KTgP3y8PO7LntSlJsDQ7AuIcdei56Z7LKhRh4EIwAI/BXEJh2UXUcFGo9vB56AI+eJKtCc4CPQ9/rB/bPZPUDhcpTyikCqwluvTpOhDnIcVCq+RgKy9PsDq2KeusuuDVcjo7nzXvRb6nF3nFx6vWxENAvx6F5FtwiztsjvItz6zcM2w2cagzkOX+grouIbTHwcWawaieYAGe4b5ZREmTjltG6m8ke3sc38OtFdVzgXGniepKM6ftdQ8miPY7cPf5zMWjjwsipjFZvgg+s8NQmmbqoNu/SSW95hws51jae493zkS0IMFltAYhPMwKZILB6hF90cOoN8CrWzVkPZ2Lhcly5qJ51p/iY9+EVxbEmhslrayZDyayTuVh8i/Af53hoKgKuNj2cuy5OfTHPNbCe4FKa2RxcdG/gl8WC3sPzfC1YLbiuOw0N6+PRw4lTw9V0jdduJVEj+d0po1D08bTsoyWxLKPl1VFyK2gPZlJ7WU/amkyTMf3lqXFf3G22Ab72aigUG7gez7HGCr+8oiI510Wh6GG4XOK5U5OyrEbmEkxsjEtJvjVcvwVH+dtuCDBZ7YYTt2IE9kBgJRflUss2/8xwXVMLZaF+gwVo70QcO/z+yR6TMZdKspBjB2jRFxrjWU9pONTQPnfiPYZMYJIEBNGEzHBjXBYDh4cnX2udtR7+UKergSQo5RTxCF+SlcCuhuvQ7YNz/iNdTJ+BDOLnqA2ASQdVQZx2v2TSc1y0R8DHoKkIVWhyqVqadb+R1T9/3QkBJqudYOJGjMAeCEgtqoyrkPIwgKcXWLW4z3HfUORVjSzoe9z5gJdO0C0TMc1wVdHE2+yHyEgMYNjS54px85ckvChZSSLw8EuOXnvRRb31ZBtN6rMuTjWWrX5EJV2R1uUgTkik6VTCRBRBTZJtZJ/JaHuOHue4jRMxBrceIctwZ4RFbJzhZvwrAQEmqwRQ+BAjkCkCqymeRtPwIi7f1sUiXkZ3sv1uH+MOzssVtHOzn7XCy2iEF8ENtBfjOPBjGgMRgoPTrq2aiDkvDUEXbJKbjzEcKzfyQGOJaJtWG9p3Kjhe3C183NZ7V0k4k9YV1cbC8liMB3gOebUrTVlokaFxhy9L/EVaZlT7TGzMB0MIMFmF4OAfjMD3IPBH7IFIbYA0iM33/d0WeyQVdCdir2f7v8VdwzgYqPto7UZrINuOleKsk35TYxJr4iGi2Nh7c5dRHwZL60neM1phqPfCNpECEUBSG6O5uXGtDtiNrOITHxmz42dJh8b62eviY/j3jjBZ/Xsy5xn/dQSsN/PGnfKS++tj+voADCGE9p1Ufx992suJE1mgNdVxG9Jc9FjmNzjX5Joem6TMkYJ84wQQnEsm3y+SldGKXcQIeAuMTFZbANpwmslqAzh8ihE4DALpprGP6QhP06h6cphRZNPrm3EUSXIseNLedsKBwjhHyBtbWpN20kDEXEqZJYR5T+5fifODcdjN/S3wqowRh0UqwglC/Aub9IjMNu9ZqSuD/wOzYwvD4DCAOZ6j4wudD/bveM8qAswOP5msdgCJmzAC+yDwMfK1+7Ted7EW0fACqzwCbddnEWt0XqmgasUR7TOWzK+1THlxBwYiAwfVTmRjzrqO0hzJDA9EXJZ3JGlFkrwi6YoCzS1KHABljDApjuTemvLeUzgERBsfOyE1w21deSOetMUc0rVipSkmu8ir3ixvwJhnIt2PP9MQYLJKQ4aPMwKZIGAtbtqt+qVb1vtV4Y19tfBa5jKRXUHEEa31ol/ppgecZjLWL3RiHBgiDhCiK9vxIro4m30ubQIUcWiuA2PuszQmpRUpDGwiF7cwhBQzpwbEQBqfNFeWu3ixpkmaX/KeGbmt6/0+7xHQLvNyz0/8Nv/0+KKkbM6LL6RRh+UeasI/UhFgskqFhk8wAtkgoBbEIrz+HB/TLs6cIqoyUNaFNxDBqCu8ykwQIsA2MAH+7tbQunvTcT4J2kk2w9urF+PCnUSkg5YmZYuA6W6U5shpYbgWQcXFcKyVIYUKrqZLDEUQbsz1PXCZj2luCMyMp90p3scdibsf8aYkkx4RGg3PfGrSLNU6eF7qcZTLyk291sWLiHuej3EltK+EPTvTj/hC5J3o7BFqyT8SEGCySgCFDzECmSKwekTbStPj9+fAeopbShVEKYHGyVkUVFBsJCg10wF+vTPlpeji/Cbqlh4Eylb9UdhtX95uhd+9Jqoyo4PIanEjF357JIu+Z9Iylepd/A54XDebyOBhEdt0G789MH9Eu2ansUrAl0hzA9G89hpBiiw9jvdR26SCopRRf7Y5apI2GYnZsufM39MRYLJKx+Yoz6ynd+j2xpl4mK3fBuj2dE63o0TjBwyaNIx61EHhB8wtF1OgzCEJZsyMx0cmS2PqzLj/n94dk9UPkvDHRJs6LFPSftNTdv+TxobknPvdgK/eggC5d1/0V/gYeDjbJYJ4S598OowAeR2So0f4bFa/uJ7VvkgyWe2L4M7XU0yHi5OyyggdjwvZubN4Q50YNW67jzf91BHttRXN6fapPrjxlxFQcTkNPCxnuKrl0xT45cnl5ULt3FEod/D7QGMir8VM/+YPNNa8dstk9W2SWeNjPsdrv6k2ZxODGL86GLGQOTjUHxv9oXFsyFfl8/XrRJqlM7eIaqWC1s0U27ZFvn6nf/vKwz7j2puzlkNvziMSO5PVtwuLNKykiPuvDYYyVx+OTPQfW9FLqCn0tTHzVYxAvhCgsh8Jnot7DlRl+GB39T1hBJPVvgh++vqsyep7bOHfY9f/NJh8ASOQIQIz3DciLvR79k51ubopxR/37P6fupzJ6tvFnS1Z0QZ8apxIVvOjGJFIUGVW3XM/jEA+EFjiqdfB8C0Lg+sSz70O7qdZ9JUPdP7mKJisvh39LMkqCHxMTxeT1QQpI0C0LlNW/XM/jAAjwAikI5AbsqJsxCURHS4CBb2+DBo8NUGDvXhQ4HyEq2bFBOwV3Aou2gNEg/PWb4+49uqoFkXmgDJKoux2o4VWJXnfSMQXXTZEPjadZkVucDdwOXgLb3Cv3zBsN3Ba1IGHIkO0W8a5d4PnhPhDJYZtZLXCS9/HeZn6dHFS93CbGDBK6Vu2x4h8TG7g15UXoiilfuYPZELQ17tmEHhZa2/ck6I4kdTUNOnPGZ9hBBgBRmAvBHJDVuvVHItZH62iVXen6GE48E1dHtstW9iCq4Icik08zERo+xLPHV0jqGK5oGqXblFS/N1AFbSNupK+9urqfsUGrsdzRU5WJdKLO6plYBWOM8k3V3i5aWypGLqJrGa41kkzzzpjLEQqlzfCpIjWgO6tJ6LnVtiSvkXZzSvwBzOZSYAcMgquIMQarqYrLPotNe4N0fWUmqbgxSrsGWT5CyPACDACh0AgN2RFkyMNS7z9yzxp8ztcSA2nHFRJNRmbi5F6MnPc1hXZUcJLqrUTN5Mpx4QQWVFp6kj1VrNIC3I0C3VQgM2UMJCTCExzBUNiNDvxmU5WNNZC4y5cBmFEhB3J6EzpWzakioHESuSgs3LVEMlRqXBKOSPmF0sIao3dul+43IPVJvrVqkm0reBf+nnxLLDdPwot/2YE/iUEckxW8ZT/JBiVKy05rsgk1tQBfob8dNJJ6kNoYg+tMrw+2esCoouRzGqCe7+Bi2YHvyzl5ne3IrWwqvcYzn1mEnjWcP0W3FF9SyEra1GPu6AP4AkicRzY5wyJtgbRm5jfUouKOkXY4xM51cQLgey/HEqkajqhL6RhHjB4km7Fn4wAI8AI2Ajkl6ySsjjLkdM+jYNC0iJNb/+Oipcgbzn11q72qi57fTxL06EFhSlJkEF2azOGpNiKZLIyxOMkFYIj54bw2Iw5L1SqwJoTgKRifkaD+yzpGI1st1Ls4ZF87690Lc0yM+sXAG7LmPAz4HzvH+gX7pZfskozbZEL9daFhrQaEexH9YPCf5TVppXzzhBMstNFOrZrLCYDXLebOC+XA6cMOb7dyYqcF7b+0RgzJLALWcXHHRScK2wgufh1AI6IrBLHzwcZAUbgaBE4PrIyC6bYP7KLn22WwfuUCIU84hRxnXi6fMEXyOpj0kNL1iVyUKp5uB5M8Ge5Akxfu5OVMVfqAn2bZ6POfomszH6fg0979Rns869Z7YIft2EEGIHjQeD4yMpyUCg0++G9ogTcXwdtXN5Nwu3W88Bz0NFu32Yhtp0oEjqkQ+O2LlXu4Kwbydn2BbIyxBNx7qDbJX1SPrNEc2jSBeKYqewaNTeu8DIa4cXyw4h1wXtWMUj4ACPACHwPAkdIVpa3XZrL9mqEa7+H5xWgNJYkTUDnuzOaDNW1SXbckOKY3qHt3+EFltt60r5PiKzecN8sq4qvspPkPStYHnlpGs9rv43LgVVlbuSpSqxpJlOs8ORrE6j28jP7VVHs5P23BPzSvFLvl/DQWo4jW02cqaZd9gZMQJYPMQL/FAJHSFb23knYO44kJxdk7QFH5jXbi06102Tl+njSF6p4JGUeDLm0y/MrDFsuStLzbzNZGUKQRKicI4L+UshKEIso3S0W7CQC1Oa7UOE2cgqJEg8BYZn8VMlti5BDhLPCQ9PBNk3VOIF8wvxKQ+FPRoARYAT2QSA3ZCWDguciKFY7QZR9/HqbYzGf4yMhxOZj1MapfBMvo9V9xOtKNKKg3GCviMhKBL92KchXtOs1pNt5QCIKRhMU7BRxIfsFQGbDoodf2kz2MfKCUh8dXZlXtBMlsIsVnRXChXd3B8910Br8T5YIWcx6ONcaRNV/xJ/5HO/G9KYTacoy5z4eJnNpvlzPH3FZcRCvKUWekWkZLHQsWLGFh/kKL90aCsWyMl+6LQyF1/5qJl34C9bc0h4ocgJJ0/zSruPjjAAjwAjsi0BuyCoglbDHntA04gG9etrLKR5EuiNKTZSQ6kj0W6r38Gvg49xKi1Qq19GOpk/S3b5P+zLdkkz7JIijnJzGSaUwKpsMGzLVkt+X+z4fj772DCzjvCOcOAKNKmoOCxPmGn8ee/DrOu2U4+KkkpDqSY41MImmYSTGoVJWiXl4eJgD6+kNWoSZ4+K02duQHooeMXKf32IqpOb8yQgwAoxAhgjkhqwynNM/1RXFkXHW9X9K7AmT5WzhCaAc4SGWY5rQmKzSkDma41zP6mhEdbCBzvHQPEQdpgouR8ZGfbDRc8eEAMuRkEj6ZLJKQuXIjpHbe9yJJKuJkDNKsGeXVc/cz74IcIXbfRHMx/Usx21yYLLahtBRnNdkkuRFmMH4VTxXJBluBv1yF/sj8DFoyT3Tw7yoHPa52n/239XDTIaflBwX1c74IDdlOW6HlclqO0bH0UIHNdtlVDIZuHZ/j3siZtI7d7IPAqtH+KIiwYFeUsTQKPA87AS0z6CP8FqKZxRevBtK6Hx5ZizHnaBjstoJpuNopNz5i5szp39qKsoD8KTZD5cs+VQf3PhQCCxu6jIu7/zGKgWQ+c2+Z08082Fn2eFqjG69jNNGZ2Nx0q/ekuW4G3JMVrvhdDSt1tM7dHs67mvPUYuKyd3eyCpauWeHfHmGCFCAd1qMXXa3ovi6UEB6dt3/4z2xHHd9AJisdkWK2zECeUKA0nOFMpEcaICUZusQJrADDfloumU57iwqJqudoeKGx4zAot/SiYddnHrarLkc49arg4K/C24R522tSa7fMBQB57JKtQN5zh9sNofOR7i2+iuVm7ifzvHS7+F6lGyqWwzauKi4Ks2WW0arJ5Iur/DUpnG5CJWy0UKg1Ffb4+vmoXmIMV1PVsBqhMu6rkAg7ntn5ZyMCprK8qSl9Yq2/8bfh5TrYuDjTMu/VGsnmADJ8UI8HwGG7+Mb+IStzEajMU/AheWYAErKISarFGD48A9CQFZCFnt5Io5FZUipNj2cuy5O/YFK1bWe4FKXe7no3sAvC5Lo4Xku0ngtg+u600RgRF7JqtiALzbx8KauGVKuR5leyzM5KKkDGXJQbOBapgEj12UHJdeFSH81XC5ldYCS46AauS9lfNmc+krvOTb0PMRGflHM30XJFem7BnhfjtGtCbLclJmE0npRjTiawV/+PKBcVZ7QGq6ma5jq4xHNUuYALfp4WvbRkjIuo+XVUXIraA9mKlXahKozNDFMCFljOe7+DDFZ7Y4VtzxSBOSiUr+RWhEtDiLlVdTDzT4X9X6kWDaVEDgCxLit80QGOSllCzuRcLSczaSDqlPDla3QkLnNcdEeAZSdRIw1rEFR6qsNqcgAyHnXuni1hmvmKBM4B+m6BIFdpnplW/cbWZ395a+Hk+sYl0UH5Ljy5GvNt9bDH5rzaiAJSrWxU6lFngErzVo8JZqF64bSfD9djgTptk8mq20I8fkjR0DFCilimuGqonNPRskDwLClzxXbeI7MWi4Y4u05tkekFjZJKH50JR/Ak2/cKcQYeVM3b/COLmlDJOjWcW2TGkjTidYkswetFtCwU4Q1f505/7mtMv2L/Jk2qdk9ie+EzWHiuaJ32+X3AeUqXxqorJD2hnQC8pKjk22oFl5XJ9VOqAJhvbDEyYrluIukqQ2TFSHBnz8UAauoJO29iOTIUV4xBODgtBtiBmkGvG8kkxy5HQszWncSgVBqT8rsFtVaFuMBnkPbWLpMiyC3BCIN90xv8tG3eLvVHM+DcXiPzVo4P0s6pJFFtVH7jt/7/YBynY8xHCvhBNptxOvSakP7TgUnbuoNip0mPB9G6/qX5bj7U8NktTtW3PLYETBmtiYeovsHplJ0gjnMWuTDe0SBGaeQ4HxgL2K/tmKny7kkmCfjl+5CVvGrYIJbNy2OCdeBipjGNcTk1sDiTpXgiVYY2PV3Kf42kXYrIHO50q0sM+mGFwgi8qSXDKORJzwf2ImsaCzW5zfK0brrX//KZPXXRcAD+C4EzMIRM+UFmRoKTpzIgrfrOm5tbcgisfhCZWlKukrzxnlu0MLi132NrMz8ExfO+F3sI7Qg50ezCkZn5pWVXKlrq8p12JxKDcSnTkmV+JIRnEsmX5ajjeS270xW2xDi8z8EgTdc15QpL+ysoKb35Gkzn72JLk9Zb9faSQOrKZ5GU3wYbUxoHG8RnGg/IjArxk1/wSWBFtbCMDgMIMGcZxbITXtWoU7CpszWIHzSMmmFTwS/8rdnRWM7gFx114GJV+9fCblHTatUrTvJQcV6AREOM+Jf+BkgMmM5asg3fjBZbYSHT/4YBCwtKL7RTYuGg1huRes68g6TGR0Ecdl7YFFvLmuhkvtVuh917xlu68rD7KQtNrrStTCl1UXdnoMFOj4XLbHZDc5ljFARl/IW5F7tIGzK1GQccfYIyz0wd6beL3zB9/2y5BMf2xflKkdPmSUckFYkyUt6UQbTo9yJBSf6kgFQ5o8CXSOfF+XpqXpgOQZIbv/GZLUdI27xExAYt3VF58hGuZjbJtIx+yHaBKiTjiqzULCgeSFlJVjcjVlR9qNJxxCZg4LwytNu0HI/R3vpKcjVYhsjUACkCYaJJxCUMY3pStuBKTPi7i7HkrT5H/QF43zy+b0uu5eDfD+IXAFYGpPSirQsIvFuhpBipt7gGSBNXsqk3MWLBQTL0QJjy1cmqy0A8emfgYBxC6+E447k7AYtlUEiYb8KlA5HvDmv48XxhCOBJJmGiuNaz8e4ElpTuaxjr+q4fVML10lbBzLphbBU6+B5uYQMHqb2tS5e1oDpJ2EfRoyZzIa0EEal9KdXk8G/Z50x3pcDGQxcLSs39bPuFGussRh3pfa1dR+KyPwLe13RcWX9+1ByDV4gKriaahnFQhqCUID4C0VgPj7tTvE+7uDMKcKPFLNkOe7+RDBZ7Y4VtzxiBH7LeCIX5zdRt/Qg+Lbqj2TWgfA0V/jda6IqTWoiq8WNJJOgzRp/rLQ8Iu3ORUelbFr0PX2dg2gc02uvYdI8lepd/F4B76O2Se9D6Z3+iGQYSf+IRFPIDJjhuqHTKTkuzrsijdMST+2a1jAdlIp1tAdvSLuFuS1plxtNhab1t345nFwBIT9Kt0UyCk9uIoOHC24dt/HHCpg/oi2zg4h0TDVcjpbhy8UvlmMck5QjTFYpwPBhRiDfCJAJMsGsmfHAydSV7hGX8Q3/qe5YjruKm8lqV6S4HSOQMwTIW40cPw4zPK5ndRhcg15ZjgEWm74xWW1Ch88xAnlGgCvM5lk6u4+N5bgTVkxWO8HEjRiBfCJArtOfTZ+022y063ckGe5u13KrzyDActyOFpPVdoy4BSOQYwSotEg888a+g1bu7zl0V993Yrm8nuW4TSxMVtsQ4vOMQO4RmOG+UUzICP/1gVM9p64o1Mj/vgkBluMmoJmsNqHD5xiBo0FgiadeB0NZ+HHfQS/x3OvgfrrVqX3fG/H1MQRYjjFI9AEmqzRk+DgjwAgwAoxAbhBgssqNKHggjAAjwAgwAmkIMFmlIcPHGQFGgBFgBHKDAJNVbkTBA2EEGAFGgBFIQ4DJKg0ZPs4IMAKMACOQGwSYrHIjCh4II8AIMAKMQBoCTFZpyPBxRoARYAQYgdwgwGSVG1HwQBgBRoARYATSEGCySkOGjzMCjAAjwAjkBgEmq9yIggfCCDACjAAjkIYAk1UaMnycEWAEGAFGIDcIMFnlRhQ8EEaAEWAEGIE0BJis0pDh44wAI8AIMAK5QYDJKjei4IEwAowAI8AIpCHAZJWGDB9nBBgBRoARyA0CTFa5EQUPhBFgBBgBRiANASarNGT4OCPACDACjEBuEGCyyo0oeCCMACPACDACaQgwWaUhw8cZAUaAEWAEcoMAk1VuRMEDYQQYAUaAEUhD4P+blA6NMIzX6AAAAABJRU5ErkJggg=="
}
},
"cell_type": "markdown",
"id": "a3c1726a",
"metadata": {},
"source": [
"- "
]
},
{
"cell_type": "code",
"execution_count": 81,
"id": "acb03440",
"metadata": {},
"outputs": [],
"source": [
"rescale <- function(x){\n",
" (x - min(x)) / (max(x) - min(x))\n",
"}"
]
},
{
"cell_type": "markdown",
"id": "9a39ced6",
"metadata": {},
"source": [
"### 使用宏包的函数\n",
"#### 安装宏包与使用宏包\n",
"- 安装宏包 `install.packages(\"dplyr\")`,也就是说宏包就是别人已经写好了的函数的集合\n",
"- 加载 `library(\"dplyr\")`,和python中的`import pandas`一样的效果‘pandas’为包\n",
"#### 指定函数的所属宏包\n",
"- 其它宏包可能也有`select()`函数,比如`MASS`和`skimr`,如果同时加载了`dplyr`,`MASS`和`skimr`三个宏包,在程序中使用`select()`函数,就会造成混淆和报错。\n",
"- 这个时候就需要给每个函数指定是来源哪个宏包,具体方法就是在宏包和函数之间添加::,\n",
"- 比如`dplyr::select()`,`skimr::select()` 或者`MASS::select()`。"
]
},
{
"cell_type": "markdown",
"id": "4b4ac114",
"metadata": {},
"source": [
"### 获取帮助"
]
},
{
"cell_type": "code",
"execution_count": 84,
"id": "fd83004a",
"metadata": {},
"outputs": [],
"source": [
"?sqrt()\n",
"?scale()"
]
},
{
"cell_type": "code",
"execution_count": 97,
"id": "5b1903f6",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"10"
],
"text/latex": [
"10"
],
"text/markdown": [
"10"
],
"text/plain": [
"[1] 10"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"10"
],
"text/latex": [
"10"
],
"text/markdown": [
"10"
],
"text/plain": [
"[1] 10"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"get_var <- function(x){\n",
" n <- length(x)\n",
" y <- mean(x)\n",
" var2 <- sum((x - y)^2) / (n - 1)\n",
" return(var2)\n",
"}\n",
"\n",
"var(c(2,4,6,8,10))\n",
"get_var(c(2,4,6,8,10))"
]
},
{
"cell_type": "code",
"execution_count": 91,
"id": "c13cd5f6",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"0.00238751147842057"
],
"text/latex": [
"0.00238751147842057"
],
"text/markdown": [
"0.00238751147842057"
],
"text/plain": [
"[1] 0.002387511"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"get_bmi <- function(height, weight){\n",
" weight / height^2\n",
"}\n",
"get_bmi(165, 65)"
]
},
{
"cell_type": "code",
"execution_count": 108,
"id": "64c10e1f",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'NA'"
],
"text/latex": [
"'NA'"
],
"text/markdown": [
"'NA'"
],
"text/plain": [
"[1] \"NA\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"mean_above_threshod <- function(vector, threshod){\n",
" upthreshod <- vector[vector > threshod]\n",
" if(length(upthreshod) == 0){\n",
" return(\"NA\")\n",
" }else{return(mean(upthreshod))\n",
" }\n",
"}\n",
"\n",
"vector <- c(2,3,4,5,6)\n",
"threshod <- 6\n",
"mean_above_threshod(vector, threshod)"
]
},
{
"cell_type": "markdown",
"id": "dc7be121",
"metadata": {},
"source": [
"## 函数应用\n",
"### 灵活的语法\n",
"- R语言中,完成一件事情往往有很多种方法\n",
"\n",
"### 多个参数\n",
"\n",
"### 条件语句\n",
"- `if-else`语句\n",
" - `if(condition){\n",
" Do something\n",
"} else{\n",
" Alternative something\n",
"}`\n",
"\n",
"### 返回多个结果\n",
"- 如果要返回多个统计结果,可以把结果先放在`list`或者`data.frame`中,然后再返回\n",
"\n",
"### 函数默认值\n",
"- `function(multi = 10)`这样的表达式"
]
},
{
"cell_type": "code",
"execution_count": 109,
"id": "0ea283eb",
"metadata": {},
"outputs": [],
"source": [
"### 灵活的语法\n",
"mysquare <- function(x){\n",
" y <- x^2\n",
" return(y)\n",
"}\n",
"\n",
"mysquare2 <- function(x){\n",
" return(x^2)\n",
"}\n",
"\n",
"mysquare3 <- function(x){ return(x^2) }\n",
"\n",
"mysquare4 <- function(x) return(x^2)\n",
"\n",
"mysquare5 <- function(x){\n",
" x^2\n",
"}\n",
"\n",
"mysquare6 <- function(x) x^2"
]
},
{
"cell_type": "code",
"execution_count": 111,
"id": "64b1d30a",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"3"
],
"text/latex": [
"3"
],
"text/markdown": [
"3"
],
"text/plain": [
"[1] 3"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"3"
],
"text/latex": [
"3"
],
"text/markdown": [
"3"
],
"text/plain": [
"[1] 3"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"### 多个参数\n",
"sum_two <- function(num1, num2){\n",
" sum <- num1 + num2\n",
" return(sum)\n",
"}\n",
"sum_two(num1 = 1, num2 = 2)\n",
"sum_two(1, 2)"
]
},
{
"cell_type": "code",
"execution_count": 114,
"id": "71ba20ff",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'Your input is not numeric.'"
],
"text/latex": [
"'Your input is not numeric.'"
],
"text/markdown": [
"'Your input is not numeric.'"
],
"text/plain": [
"[1] \"Your input is not numeric.\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"9"
],
"text/latex": [
"9"
],
"text/markdown": [
"9"
],
"text/plain": [
"[1] 9"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"### 条件语句\n",
"square_if <- function(num){\n",
" if (is.numeric(num)){\n",
" num^2\n",
" } else{\n",
" \"Your input is not numeric.\"\n",
" }\n",
"}\n",
"\n",
"square_if(\"a\")\n",
"square_if(3)"
]
},
{
"cell_type": "code",
"execution_count": 119,
"id": "dca917c0",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"3"
],
"text/latex": [
"3"
],
"text/markdown": [
"3"
],
"text/plain": [
"[1] 3"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1] \"Your input is not numeric.\"\n"
]
}
],
"source": [
"sum_two <- function(num1, num2){\n",
" if(is.numeric(num1) & is.numeric(num2)){\n",
" sum <- num1 + num2\n",
" return(sum)\n",
" } else{\n",
" print(\"Your input is not numeric.\")\n",
" } \n",
"}\n",
"sum_two(1, 2)\n",
"sum_two(1,\"x\")"
]
},
{
"cell_type": "code",
"execution_count": 124,
"id": "710f870f",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1] \"Zero\"\n"
]
}
],
"source": [
"### 多个条件\n",
"check_number <- function(x){\n",
" if (x < 0){\n",
" print(\"Negative number\")\n",
" } else if (x > 0){\n",
" print(\"Positive number\")\n",
" } else{\n",
" print(\"Zero\")\n",
" }\n",
"}\n",
"\n",
"x <- 0\n",
"check_number(x)"
]
},
{
"cell_type": "code",
"execution_count": 126,
"id": "f294a534",
"metadata": {},
"outputs": [],
"source": [
"### 返回多个结果\n",
"mystat <- function(x){\n",
" meanval <- mean(x)\n",
" sdval <- sd(x)\n",
" list(sd=sdval, mean=meanval)\n",
"}\n",
"\n",
"mystat2 <- function(x){\n",
" meanval <- mean(x)\n",
" sdval <- sd(x)\n",
" data.frame(\n",
" sd=sdval,\n",
" mean=meanval\n",
" )\n",
"}"
]
},
{
"cell_type": "markdown",
"id": "11793a30",
"metadata": {},
"source": [
"## 子集选取\n",
"- 对象就是我们在计算机里新建了存储空间,好比一个盒子, 我们可以往盒子里面装东西(赋值),可以查看里面的内容或者对里面的内容做计算(函数),也可以从盒子里取出**部分东西**(子集选取)\n",
"- **子集选取**,就是从盒子里取东西出来\n",
"\n",
"\n",
"### 向量\n",
"- 对于原子型向量,我们有至少四种选取子集的方法\n",
" - 正整数: 指定向量元素中的位置 `x[1]`\n",
" - 负整数:删除指定位置的元素 `x[-2]`\n",
" - 逻辑向量:将`TRUE`对应位置的元素提取出来`x[x > 3]`\n",
" - 我们可以用命名向量,返回其对应位置的向量\n",
"### 列表\n",
"- 对列表取子集,和向量的方法一样。向量的子集仍然是向量,使用`[`提取列表的子集,总是返回列表\n",
"- 如果想提取列表某个元素的值,需要使用`[[`\n",
"- 取出`one`位置上的元素,需要写`[[\"one\"]]`,太麻烦了,所以用`$`来简写\n",
"- `x$y` 是 `x[[\"y\"]]`的简写"
]
},
{
"cell_type": "code",
"execution_count": 137,
"id": "da5d4409",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\t- $one
\n",
"\t\t- \n",
"
- 'a'
- 'b'
- 'c'
\n",
" \n",
"\t- $two
\n",
"\t\t- \n",
"
- 1
- 2
- 3
- 4
- 5
\n",
" \n",
"\t- $three
\n",
"\t\t- \n",
"
- TRUE
- FALSE
\n",
" \n",
"
\n"
],
"text/latex": [
"\\begin{description}\n",
"\\item[\\$one] \\begin{enumerate*}\n",
"\\item 'a'\n",
"\\item 'b'\n",
"\\item 'c'\n",
"\\end{enumerate*}\n",
"\n",
"\\item[\\$two] \\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\item 5\n",
"\\end{enumerate*}\n",
"\n",
"\\item[\\$three] \\begin{enumerate*}\n",
"\\item TRUE\n",
"\\item FALSE\n",
"\\end{enumerate*}\n",
"\n",
"\\end{description}\n"
],
"text/markdown": [
"$one\n",
": 1. 'a'\n",
"2. 'b'\n",
"3. 'c'\n",
"\n",
"\n",
"\n",
"$two\n",
": 1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"5. 5\n",
"\n",
"\n",
"\n",
"$three\n",
": 1. TRUE\n",
"2. FALSE\n",
"\n",
"\n",
"\n",
"\n",
"\n"
],
"text/plain": [
"$one\n",
"[1] \"a\" \"b\" \"c\"\n",
"\n",
"$two\n",
"[1] 1 2 3 4 5\n",
"\n",
"$three\n",
"[1] TRUE FALSE\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"$one = \n",
"- 'a'
- 'b'
- 'c'
\n"
],
"text/latex": [
"\\textbf{\\$one} = \\begin{enumerate*}\n",
"\\item 'a'\n",
"\\item 'b'\n",
"\\item 'c'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"**$one** = 1. 'a'\n",
"2. 'b'\n",
"3. 'c'\n",
"\n",
"\n"
],
"text/plain": [
"$one\n",
"[1] \"a\" \"b\" \"c\"\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"$one = \n",
"- 'a'
- 'b'
- 'c'
\n"
],
"text/latex": [
"\\textbf{\\$one} = \\begin{enumerate*}\n",
"\\item 'a'\n",
"\\item 'b'\n",
"\\item 'c'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"**$one** = 1. 'a'\n",
"2. 'b'\n",
"3. 'c'\n",
"\n",
"\n"
],
"text/plain": [
"$one\n",
"[1] \"a\" \"b\" \"c\"\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 'a'
- 'b'
- 'c'
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 'a'\n",
"\\item 'b'\n",
"\\item 'c'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 'a'\n",
"2. 'b'\n",
"3. 'c'\n",
"\n",
"\n"
],
"text/plain": [
"[1] \"a\" \"b\" \"c\""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 'a'
- 'b'
- 'c'
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 'a'\n",
"\\item 'b'\n",
"\\item 'c'\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 'a'\n",
"2. 'b'\n",
"3. 'c'\n",
"\n",
"\n"
],
"text/plain": [
"[1] \"a\" \"b\" \"c\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"l <- list(\n",
"\"one\" = c(\"a\", \"b\", \"c\"),\n",
"\"two\" = c(1:5),\n",
"\"three\" = c(TRUE, FALSE)\n",
")\n",
"l \n",
"l[1] # 使用位置索引\n",
"l[\"one\"] # 使用元素名\n",
"l[[1]] # 提取列表某个元素的值\n",
"l$one"
]
},
{
"cell_type": "markdown",
"id": "a089a0cf",
"metadata": {},
"source": [
"### 矩阵\n",
"- `x[a,b]`用于选取,`a`为行方向,`b`为列方向\n",
"- `x[a, ]`,表示列方向选取所有列,反之\n",
"- `x[, ]` `x[]`,表示取整个矩阵"
]
},
{
"cell_type": "code",
"execution_count": 144,
"id": "2a691774",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"\t| 1 | 2 | 3 |
\n",
"\t| 4 | 5 | 6 |
\n",
"\t| 7 | 8 | 9 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 3 × 3 of type int\n",
"\\begin{tabular}{lll}\n",
"\t 1 & 2 & 3\\\\\n",
"\t 4 & 5 & 6\\\\\n",
"\t 7 & 8 & 9\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"| 1 | 2 | 3 |\n",
"| 4 | 5 | 6 |\n",
"| 7 | 8 | 9 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 1 2 3 \n",
"[2,] 4 5 6 \n",
"[3,] 7 8 9 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A matrix: 2 × 2 of type int\n",
"\n",
"\t| 2 | 3 |
\n",
"\t| 5 | 6 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 2 × 2 of type int\n",
"\\begin{tabular}{ll}\n",
"\t 2 & 3\\\\\n",
"\t 5 & 6\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 2 × 2 of type int\n",
"\n",
"| 2 | 3 |\n",
"| 5 | 6 |\n",
"\n"
],
"text/plain": [
" [,1] [,2]\n",
"[1,] 2 3 \n",
"[2,] 5 6 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 1
- 2
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1 2"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A matrix: 2 × 3 of type int\n",
"\n",
"\t| 1 | 2 | 3 |
\n",
"\t| 4 | 5 | 6 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 2 × 3 of type int\n",
"\\begin{tabular}{lll}\n",
"\t 1 & 2 & 3\\\\\n",
"\t 4 & 5 & 6\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 2 × 3 of type int\n",
"\n",
"| 1 | 2 | 3 |\n",
"| 4 | 5 | 6 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 1 2 3 \n",
"[2,] 4 5 6 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"\t| 1 | 2 | 3 |
\n",
"\t| 4 | 5 | 6 |
\n",
"\t| 7 | 8 | 9 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 3 × 3 of type int\n",
"\\begin{tabular}{lll}\n",
"\t 1 & 2 & 3\\\\\n",
"\t 4 & 5 & 6\\\\\n",
"\t 7 & 8 & 9\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"| 1 | 2 | 3 |\n",
"| 4 | 5 | 6 |\n",
"| 7 | 8 | 9 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 1 2 3 \n",
"[2,] 4 5 6 \n",
"[3,] 7 8 9 "
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"a <- matrix(1:9, nrow=3, byrow=TRUE)\n",
"a\n",
"\n",
"a[1:2, 2:3] # 我们取第1行到第2行的2-3列\n",
"a[1, 1:2] # 默认情况下, [ 会将获取的数据,以尽可能低的维度形式呈现\n",
"a[1:2, ] # 列方向,选取所有列\n",
"a[]"
]
},
{
"cell_type": "markdown",
"id": "04cf8106",
"metadata": {},
"source": [
"### 数据框\n",
"- 数据框具有`list`和`matrix`的双重属性,因此\n",
" - 当选取数据框的某几列的时候,可以和list一样,指定元素位置索引,比如`df[1:2]`选取前两列\n",
" - 也可以像矩阵一样,按照行和列的标识选取,比如`df[1:3, ]`选取前三行的所有列\n",
" - 当遇到单行或单列的时候,也和矩阵一样,数据会降维\n",
" - 如果想避免降维,需要多写一句话`df[, \"x\", drop = FALSE]`"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "009a6add",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 3\n",
"\n",
"\t| x | y | z |
|---|
\n",
"\t| <int> | <int> | <chr> |
|---|
\n",
"\n",
"\n",
"\t| 1 | 4 | a |
\n",
"\t| 2 | 3 | b |
\n",
"\t| 3 | 2 | c |
\n",
"\t| 4 | 1 | d |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 3\n",
"\\begin{tabular}{lll}\n",
" x & y & z\\\\\n",
" & & \\\\\n",
"\\hline\n",
"\t 1 & 4 & a\\\\\n",
"\t 2 & 3 & b\\\\\n",
"\t 3 & 2 & c\\\\\n",
"\t 4 & 1 & d\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 3\n",
"\n",
"| x <int> | y <int> | z <chr> |\n",
"|---|---|---|\n",
"| 1 | 4 | a |\n",
"| 2 | 3 | b |\n",
"| 3 | 2 | c |\n",
"| 4 | 1 | d |\n",
"\n"
],
"text/plain": [
" x y z\n",
"1 1 4 a\n",
"2 2 3 b\n",
"3 3 2 c\n",
"4 4 1 d"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 1\n",
"\n",
"\t| x |
|---|
\n",
"\t| <int> |
|---|
\n",
"\n",
"\n",
"\t| 1 |
\n",
"\t| 2 |
\n",
"\t| 3 |
\n",
"\t| 4 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 1\n",
"\\begin{tabular}{l}\n",
" x\\\\\n",
" \\\\\n",
"\\hline\n",
"\t 1\\\\\n",
"\t 2\\\\\n",
"\t 3\\\\\n",
"\t 4\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 1\n",
"\n",
"| x <int> |\n",
"|---|\n",
"| 1 |\n",
"| 2 |\n",
"| 3 |\n",
"| 4 |\n",
"\n"
],
"text/plain": [
" x\n",
"1 1\n",
"2 2\n",
"3 3\n",
"4 4"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"df <- data.frame(\n",
"x=1:4,\n",
"y=4:1,\n",
"z=c(\"a\", \"b\", \"c\", \"d\")\n",
")\n",
"df\n",
"df[\"x\"]"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "8a5f279d",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 2\n",
"\n",
"\t| x | y |
|---|
\n",
"\t| <int> | <int> |
|---|
\n",
"\n",
"\n",
"\t| 1 | 4 |
\n",
"\t| 2 | 3 |
\n",
"\t| 3 | 2 |
\n",
"\t| 4 | 1 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 2\n",
"\\begin{tabular}{ll}\n",
" x & y\\\\\n",
" & \\\\\n",
"\\hline\n",
"\t 1 & 4\\\\\n",
"\t 2 & 3\\\\\n",
"\t 3 & 2\\\\\n",
"\t 4 & 1\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 2\n",
"\n",
"| x <int> | y <int> |\n",
"|---|---|\n",
"| 1 | 4 |\n",
"| 2 | 3 |\n",
"| 3 | 2 |\n",
"| 4 | 1 |\n",
"\n"
],
"text/plain": [
" x y\n",
"1 1 4\n",
"2 2 3\n",
"3 3 2\n",
"4 4 1"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3
- 4
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1 2 3 4"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"- 1
- 2
- 3
- 4
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 1\n",
"\\item 2\n",
"\\item 3\n",
"\\item 4\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 1\n",
"2. 2\n",
"3. 3\n",
"4. 4\n",
"\n",
"\n"
],
"text/plain": [
"[1] 1 2 3 4"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# like a list\n",
"df[1:2]\n",
"df[[\"x\"]]\n",
"df$x"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "5f94f1b8",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 2\n",
"\n",
"\t| x | z |
|---|
\n",
"\t| <int> | <chr> |
|---|
\n",
"\n",
"\n",
"\t| 1 | a |
\n",
"\t| 2 | b |
\n",
"\t| 3 | c |
\n",
"\t| 4 | d |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 2\n",
"\\begin{tabular}{ll}\n",
" x & z\\\\\n",
" & \\\\\n",
"\\hline\n",
"\t 1 & a\\\\\n",
"\t 2 & b\\\\\n",
"\t 3 & c\\\\\n",
"\t 4 & d\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 2\n",
"\n",
"| x <int> | z <chr> |\n",
"|---|---|\n",
"| 1 | a |\n",
"| 2 | b |\n",
"| 3 | c |\n",
"| 4 | d |\n",
"\n"
],
"text/plain": [
" x z\n",
"1 1 a\n",
"2 2 b\n",
"3 3 c\n",
"4 4 d"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 3\n",
"\n",
"\t| x | y | z |
|---|
\n",
"\t| <int> | <int> | <chr> |
|---|
\n",
"\n",
"\n",
"\t| 1 | 4 | a |
\n",
"\t| 2 | 3 | b |
\n",
"\t| 3 | 2 | c |
\n",
"\t| 4 | 1 | d |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 3\n",
"\\begin{tabular}{lll}\n",
" x & y & z\\\\\n",
" & & \\\\\n",
"\\hline\n",
"\t 1 & 4 & a\\\\\n",
"\t 2 & 3 & b\\\\\n",
"\t 3 & 2 & c\\\\\n",
"\t 4 & 1 & d\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 3\n",
"\n",
"| x <int> | y <int> | z <chr> |\n",
"|---|---|---|\n",
"| 1 | 4 | a |\n",
"| 2 | 3 | b |\n",
"| 3 | 2 | c |\n",
"| 4 | 1 | d |\n",
"\n"
],
"text/plain": [
" x y z\n",
"1 1 4 a\n",
"2 2 3 b\n",
"3 3 2 c\n",
"4 4 1 d"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A data.frame: 4 × 1\n",
"\n",
"\t| x |
|---|
\n",
"\t| <int> |
|---|
\n",
"\n",
"\n",
"\t| 1 |
\n",
"\t| 2 |
\n",
"\t| 3 |
\n",
"\t| 4 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A data.frame: 4 × 1\n",
"\\begin{tabular}{l}\n",
" x\\\\\n",
" \\\\\n",
"\\hline\n",
"\t 1\\\\\n",
"\t 2\\\\\n",
"\t 3\\\\\n",
"\t 4\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A data.frame: 4 × 1\n",
"\n",
"| x <int> |\n",
"|---|\n",
"| 1 |\n",
"| 2 |\n",
"| 3 |\n",
"| 4 |\n",
"\n"
],
"text/plain": [
" x\n",
"1 1\n",
"2 2\n",
"3 3\n",
"4 4"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# like a matrix\n",
"df[,c(\"x\",\"z\")]\n",
"df[,1:3]\n",
"df[, \"x\", drop=FALSE]"
]
},
{
"cell_type": "markdown",
"id": "195f5f78",
"metadata": {},
"source": [
"### 增强型数据框\n",
"- `tibble`是增强型的`data.frame`,\n",
"- 选取`tibble`的行或者列,即使遇到单行或者单列的时候,数据也不会降维,总是返回`tibble`,即仍然是数据框的形式。"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "26c87dd8",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A tibble: 4 × 3\n",
"\n",
"\t| x | y | z |
|---|
\n",
"\t| <int> | <int> | <chr> |
|---|
\n",
"\n",
"\n",
"\t| 1 | 4 | a |
\n",
"\t| 2 | 3 | b |
\n",
"\t| 3 | 2 | c |
\n",
"\t| 4 | 1 | d |
\n",
"\n",
"
\n"
],
"text/latex": [
"A tibble: 4 × 3\n",
"\\begin{tabular}{lll}\n",
" x & y & z\\\\\n",
" & & \\\\\n",
"\\hline\n",
"\t 1 & 4 & a\\\\\n",
"\t 2 & 3 & b\\\\\n",
"\t 3 & 2 & c\\\\\n",
"\t 4 & 1 & d\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A tibble: 4 × 3\n",
"\n",
"| x <int> | y <int> | z <chr> |\n",
"|---|---|---|\n",
"| 1 | 4 | a |\n",
"| 2 | 3 | b |\n",
"| 3 | 2 | c |\n",
"| 4 | 1 | d |\n",
"\n"
],
"text/plain": [
" x y z\n",
"1 1 4 a\n",
"2 2 3 b\n",
"3 3 2 c\n",
"4 4 1 d"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"tb <- tibble::tibble(\n",
"x=1:4,\n",
"y=4:1,\n",
"z=c(\"a\", \"b\", \"c\", \"d\"))\n",
"tb"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "d5458ba9",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A tibble: 4 × 1\n",
"\n",
"\t| x |
|---|
\n",
"\t| <int> |
|---|
\n",
"\n",
"\n",
"\t| 1 |
\n",
"\t| 2 |
\n",
"\t| 3 |
\n",
"\t| 4 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A tibble: 4 × 1\n",
"\\begin{tabular}{l}\n",
" x\\\\\n",
" \\\\\n",
"\\hline\n",
"\t 1\\\\\n",
"\t 2\\\\\n",
"\t 3\\\\\n",
"\t 4\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A tibble: 4 × 1\n",
"\n",
"| x <int> |\n",
"|---|\n",
"| 1 |\n",
"| 2 |\n",
"| 3 |\n",
"| 4 |\n",
"\n"
],
"text/plain": [
" x\n",
"1 1\n",
"2 2\n",
"3 3\n",
"4 4"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"\n",
"A tibble: 4 × 1\n",
"\n",
"\t| x |
|---|
\n",
"\t| <int> |
|---|
\n",
"\n",
"\n",
"\t| 1 |
\n",
"\t| 2 |
\n",
"\t| 3 |
\n",
"\t| 4 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A tibble: 4 × 1\n",
"\\begin{tabular}{l}\n",
" x\\\\\n",
" \\\\\n",
"\\hline\n",
"\t 1\\\\\n",
"\t 2\\\\\n",
"\t 3\\\\\n",
"\t 4\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A tibble: 4 × 1\n",
"\n",
"| x <int> |\n",
"|---|\n",
"| 1 |\n",
"| 2 |\n",
"| 3 |\n",
"| 4 |\n",
"\n"
],
"text/plain": [
" x\n",
"1 1\n",
"2 2\n",
"3 3\n",
"4 4"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"tb[\"x\"]\n",
"tb[,\"x\"]"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "2620c5cd",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"\t| 1 | 4 | 7 |
\n",
"\t| 2 | 5 | 8 |
\n",
"\t| 3 | 6 | 9 |
\n",
"\n",
"
\n"
],
"text/latex": [
"A matrix: 3 × 3 of type int\n",
"\\begin{tabular}{lll}\n",
"\t 1 & 4 & 7\\\\\n",
"\t 2 & 5 & 8\\\\\n",
"\t 3 & 6 & 9\\\\\n",
"\\end{tabular}\n"
],
"text/markdown": [
"\n",
"A matrix: 3 × 3 of type int\n",
"\n",
"| 1 | 4 | 7 |\n",
"| 2 | 5 | 8 |\n",
"| 3 | 6 | 9 |\n",
"\n"
],
"text/plain": [
" [,1] [,2] [,3]\n",
"[1,] 1 4 7 \n",
"[2,] 2 5 8 \n",
"[3,] 3 6 9 "
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"7"
],
"text/latex": [
"7"
],
"text/markdown": [
"7"
],
"text/plain": [
"[1] 7"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"mt <- matrix(1:9, nrow=3)\n",
"mt\n",
"mt[1,3]"
]
},
{
"cell_type": "code",
"execution_count": 29,
"id": "dbebc12a",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"- 3
- 5
- 0
- 2
- 0
\n"
],
"text/latex": [
"\\begin{enumerate*}\n",
"\\item 3\n",
"\\item 5\n",
"\\item 0\n",
"\\item 2\n",
"\\item 0\n",
"\\end{enumerate*}\n"
],
"text/markdown": [
"1. 3\n",
"2. 5\n",
"3. 0\n",
"4. 2\n",
"5. 0\n",
"\n",
"\n"
],
"text/plain": [
"[1] 3 5 0 2 0"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x <- c(3, 5, NA, 2, NA)\n",
"x_missing <- is.na(x)\n",
"x[x_missing] <- 0\n",
"x"
]
},
{
"cell_type": "markdown",
"id": "a0004a37",
"metadata": {},
"source": [
"## 可重复性文档\n",
"### 什么是`Rmarkdown`\n",
"- \n",
"### `markdown` 基本语法\n",
"- 如果想制作简单表格,\n",
" - 列与列之间用 `|` 分隔,表格的首行下面添加`--------`\n",
"- 如果想添加网页链接,可以用方括号和圆括号\n",
" - `[Download R](http://www.r-project.org/)`"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "96140bd6",
"metadata": {},
"outputs": [],
"source": [
"# This is a title\n",
"\n",
"# 第一章 (注意 \"#\" 与 \"第一章\"之间有空格)\n",
"## 第一节 (同上,\"##\" 与 \"第一节\"之间有空格)\n",
"\n",
"This is a sentence.\n",
"\n",
"Now a list begins:\n",
" \n",
"- no importance\n",
"- again\n",
"- repeat\n",
" \n",
"A numbered list:\n",
" \n",
"1. first\n",
"2. second\n",
"\n",
"__bold__, _italic_, ~~strike through~~"
]
},
{
"cell_type": "markdown",
"id": "896e8afd",
"metadata": {},
"source": [
"Table Header | Second Header\n",
"------------- | -------------\n",
"Cell 1, 1 | Cell 2, 1\n",
"Cell 1, 2 | Cell 2, 2"
]
},
{
"cell_type": "markdown",
"id": "bdf6725d",
"metadata": {},
"source": [
"### R Code chunks\n",
"- 在`Rmd`文档中写`R`代码,需要插入代码块(`Code chunks`),具体以 ` ```{r} ` 开始,以 ` ``` `结尾。可以用快捷方式`Ctrl + Alt + I` (OS X: `Cmd + Option + I`)创建代码块。"
]
},
{
"cell_type": "markdown",
"id": "b259931d",
"metadata": {},
"source": [
"### 生成`html`文档\n",
"- 希望`html`文档有章节号、目录或者更好显示表格,可以修改`yaml`头文件(用下面的内容替换`Rmarkdown`的头文件)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3563059f",
"metadata": {},
"outputs": [],
"source": [
"---\n",
"title: Habits\n",
"author: John Doe\n",
"date: \"2023-07-18\"\n",
"output: \n",
" html_document:\n",
" df_print: paged\n",
" toc: yes\n",
" number_sections: yes\n",
"---"
]
},
{
"cell_type": "markdown",
"id": "86f96673",
"metadata": {},
"source": [
"### 生成`word`文档\n",
"### 生成`pdf`文档"
]
},
{
"cell_type": "markdown",
"id": "a1cc5b23",
"metadata": {},
"source": [
"## 读取数据\n",
"- 在学习R语言过程中,除了使用内置的数据集外,我们更多的需要导入外部数据\n",
"### 数据科学中的文件管理\n",
"- 把项目所需的文件(代码、数据、图片等),放在一个文件夹里\n",
"- 项目文件结构\n",
" - "
]
},
{
"cell_type": "markdown",
"id": "a7bc587b",
"metadata": {},
"source": [
"- 读取文件\n",
" - 事实上,R语言提供了很多读取数据的函数。下表列出了常见文件格式的读取方法\n",
"\n",
"文件格式 | R函数\n",
"----------- | ------------\n",
"txt\t| read.table()\n",
".csv\t| read.csv() and readr::read_csv()\n",
".xls and .xlsx\t| readxl::read_excel() and openxlsx::read.xlsx()\n",
".sav(SPSS files)\t| haven::read_sav() and foreign::read.spss()\n",
".Rdata or rda\t| load()\n",
".rds\t| readRDS() and readr::read_rds()\n",
".dta\t| haven::read_dta() and haven::read_stata()\n",
".sas7bdat(SAS files)\t| haven::read_sas()\n",
"Internet\t| download.file()"
]
},
{
"cell_type": "markdown",
"id": "9001bfb3",
"metadata": {},
"source": [
"### `here`宏包\n",
"- 强大的`here`宏包,`here()`会告诉我们当前所在的目录\n",
"- 指向某个文件的路径信息\n",
"- `here`宏包的好处还在于,在不同的电脑和文件结构下,代码都能运行"
]
},
{
"cell_type": "code",
"execution_count": 32,
"id": "c7b969de",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'/public/home/sll'"
],
"text/latex": [
"'/public/home/sll'"
],
"text/markdown": [
"'/public/home/sll'"
],
"text/plain": [
"[1] \"/public/home/sll\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"here::here()"
]
},
{
"cell_type": "code",
"execution_count": 36,
"id": "f3cfd0b9",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"'/public/home/sll/software/smoove'"
],
"text/latex": [
"'/public/home/sll/software/smoove'"
],
"text/markdown": [
"'/public/home/sll/software/smoove'"
],
"text/plain": [
"[1] \"/public/home/sll/software/smoove\""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"here::here(\"software\", \"smoove\")\n",
"d <- read.table(file= \"./data/txt_file.txt\", header = TRUE)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "R",
"language": "R",
"name": "ir"
},
"language_info": {
"codemirror_mode": "r",
"file_extension": ".r",
"mimetype": "text/x-r-source",
"name": "R",
"pygments_lexer": "r",
"version": "4.2.0"
}
},
"nbformat": 4,
"nbformat_minor": 5
}